Learning Outcomes
- To discuss what is meant by the term data mining, to be able to express a business problem within a data mining framework and identify an appropriate target variable.
- To be able to identify necessary prerequisites for the application of a data mining framework and discuss the limitations of data mining methods with regard to data and methods in the context of the business problem.
- To describe and analyze the organizational structure of large data sets to facilitate effective data mining and to be able to correctly interpret and critically evaluate the results to make informed decisions within a data mining framework
- To express the data mining framework for a particular business problem through the correct application of data mining tools.
- To interpret the results produced from data mining tools and evaluate the effectiveness of data mining methods and where necessary make appropriate recommendations for use in the virtuous cycle of data mining.
Data Mining Report A Patchwork Assignment
Structure of the coursework.
The coursework is an individual piece of assessment, requiring you to analyze the ORGANICS dataset within SAS Enterprise Miner or Weka, using the directed data mining techniques covered in the IMAT3613 module, and detailing your results, and interpretations, conclusions, and recommendations in a well-structured technical report. You are provided with:
- This Brief
- A sample of data from the ORGANICS dataset is shown in Appendix A.
- The ORGANICS dataset contains 10,000 observations and 13 variables. The variables in the dataset are shown in Appendix B.
- The coursework will be assessed according to the marking grid in Appendix C
- Self/Peer Assessment Rubric Appendix D
- Template Report in Appendix E
Lab Journal and Reflection
To help your produce this report in a timely manner, the report is built up from four biweekly activities. You have an opportunity to modify your work from each activity in light of your own reflection and self-assessment feedback. Ten percent of the marks are awarded for a reflection on how you have developed your report over the term. The length of this reflection should be at least 200 words and is to be included in your appendix. To help you produce this reflection you may make use of the journal feature on the blackboard and the self-assessment grid to record your progress.
The last and fifth activity is to produce an integrated report with conclusions and recommendations you will complete independently.
In the odd weeks, it is suggested that you upload your answer to the activity on the lab journal.
In the even weeks, you are expected to comment on your work using the self-assessment rubric and assign a grade of A, B, C, D, or F. At the beginning of the even weeks, a rubric will be produced for each activity to guide you in the assessment of your self-assessment. These marks are not used to make up the final mark however your engagement with the process is. This has been designed to help you structure your work and pace the development of the report over the term.
You may modify your weekly contributions through your engagement in the lab journal. In fact, you are encouraged to do so. You should treat the lab journal as a notebook of your activities for the week.
In the final exercise, you will integrate all four activities and the final activity into a report.
In each activity you are expected to produce a piece of writing from between 200 and 400 words, producing a final report to a maximum of 2000 words excluding, a table of contents, diagrams, and appendices. You are provided a template report to complete, existing words in the template do not count to the reported maximum.
This type of assessment is known as a patchwork assessment and is more UDL-friendly compared to traditional forms of report assessment.
The patchwork assessment gives you an opportunity to improve your work over the term and reduces the stress of having to produce one piece of writing at the last minute.
The final report is summative and is marked by your tutor according to the attached marking grid.
Individual Data Set
You will each individually generate a unique model set personal to you.
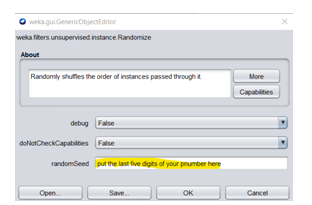
Each of you will be working on your own random sample of data generated by typically inserting the last 5 figures of your DMU student id number into the random seed generator within the Data Partition node. You will be shown how to do this in the labs.
Note: If the spurious output for any of the models should occur, insert the last 4 figures (or the last 3 figures) of your DMU student id number into the random seed generator – to enable you to generate sensible output that you can interpret.
In SAS Enterprise Miner

In Weka
If you are using Weka, you should randomize your data set before producing the training and test set using a randomizer filter. This can be found in filters> unsupervised>instances>randomizer
Submission
You will need to submit a copy of your report using the Turnitin link in the assessments section of the Data Mining module shell on Blackboard (to be made available prior to the coursework deadline).
Provision of Data mining tools and notes on using Weka
You may use either SAS Enterprise Miner or Weka as your platform to generate models it does not matter which. Weka is the alternative software option that is recommended if you have problems with accessing campus computers or you have been unable to install SAS enterprise miner on your home PC. This is likely to appeal to MacOS users who are not comfortable with setting up and using virtual machines or do not have the hardware resources to use Enterprise Miner. Weka is an open-source software from the University of Waikato.
The learning resources presented in the module schedule use SAS Enterprise Miner, and have more integrated support by way of screencast videos. If for some reason you wish to use Weka, please use the resources listed in the “using Weka” handout, note these resources are largely self-directed.
You are provided with an AIFF file for the HMEQ data set and some guidance on how you can adapt the HMEQ lab activities to using the WEKA platform. It is recommended that you use SAS enterprise miner if at all possible. Due to the effort required to learn a tool you should fix the platform you are going to use within the first two weeks. This provision is only made to those students who are facing technical difficulties with their hardware.
Note nearly everything you can do in SAS enterprise miner you may be able to do in Weka with the exception of the following functionality:
There is no means to produce non-cumulative lift charts; use cumulative lift chart, AUC, TPR and classification measures as percentages instead. Note unlike SAS you cannot compare different sized datasets in the Model performance chart, use percentages were possible when comparing
- different charts so you can make a direct comparison. Do not report frequencies but present percentages when presenting data for true positives, true negatives, false positives, and false negatives. Note that Weka uses the term sample size for depth in its generation of a lift chart, the range goes from 0 to1, which is equivalent to 0 to 100%
- The use of the test set is not integrated into Weka. You must split your data into three, training, validation, and test set. Recombine training and validation, this then becomes the input for Weka for model building. Note in Weka’s language this is called train test which is the equivalent of train validation in SAS enterprise miner. Separately you will need to create a test set that should correspond to 30% of the original data and treat this as a hold-out set. When you have selected your champion model use this to assess model performance on unseen data. You will need to use the serialized instance saver to export the model and serialisedinstanceloader nodes to score the test data. This is unnecessary in SAS enterprise miner as the test set performance is assessed directly in the model comparison node.
- The modify functionality is best used in the pre-process tab of Weka’s explorer do not use the knowledge flow to do pre-processing. Create separate model sets (Train/Test) missing values, treatment of outliers, and transformations as separate arff files. This is suggested in the guidance notes. SAS takes care of this directly, Weka does not so you will have to apply these transformations to the “hold out” set before you score it.
d)p-values for logistic regression coefficients are not presented in Weka, the advice is to use the information gain and rank on the attribute selection function in Weka, or J48 attribute selection for variable selection in logistic regression. Note the default behaviour for logistic regression node in Weka is that it imputes the mean and the mode of missing values. If you want to assess model performance on missing values you must create a separate arff file and remove these values using the filters. See guidance notes.
Scenario:
- A supermarket is beginning to offer a line of organic products. The supermarket’s management would like to determine which customers are likely to purchase these products.
- The supermarket has a customer loyalty program. As an initial buyer incentive plan, the supermarket provided coupons for the organic products to all of their loyalty program participants and has now collected data that includes whether or not these customers have purchased any of the organic products.
You are a data miner and have been commissioned by the supermarket’s manager to analyze the organic data and to provide the manager with the best model that s/he should use to identify the customers who are likely to buy the supermarket’s new line of organic products.
The analysis you are conducting will represent the first flow of the virtuous cycle of data mining.
You will be assessed on producing a technical, well-structured, comprehensive but concise report to the manager of the supermarket. This report is broken up into five activities, four of which you are encouraged to do biweekly and self-assess your work using the lab journal. The final activity integrates the pieces into one report detailing:
- Develop a description of the business problem and appropriate data mining problem and describe a data mining framework that is appropriate for your brief. Identify the target variable.
- Make appropriate use of Exploratory Data Analysis on your data set to develop insights that will inform your data mining process and suggest any transformations which might be appropriate.
- Apply regression analyses to your dataset including the full model and the Selection Methods: Forward, Backward and Stepwise. Develop a regression equation that includes only significant parameters at the 95% confidence interval.
- Conduct a Decision Tree analysis on the data set, vary the default parameters, and present an interpretation of your results. If appropriate develop a tree by hand. Identify the target path(s) and critical path.
Conduct a Neural Network analysis on the data set, vary the default parameters, and present an interpretation of your results. You may choose to try different neural network architectures. Identify the most important weights together with a diagram identifying the neural network architecture.
- Justification of your final selected model, by considering appropriate data mining strategies: Cumulative Lift Charts, Non-Cumulative Lift Charts, and Diagnostic Charts.
- Conclusions
- Recommendations on how to improve the quality of the supermarket’s data collection process in the future, to enable you as a data miner the opportunity to improve on the accuracy of the data mining model in further flows of the data mining cycle. Develop and integrate your activities into a full technical report.
In the Appendix of the report you need to include:
- A table of the model roles and measurement levels of the variables (to produce sensible analyses).
- A view of the random seed generator illustrating the digits of your DMU student id number that you have used (to produce sensible analyses).
- A copy of the process flow diagram.
A reflection of at least 200 words describing how your interaction with the discussion board modified or shaped the development of your report during the patchwork process
Buy Answer of This Assessment & Raise Your Grades
The post IMAT3613: Requiring you to analyze the ORGANICS dataset within SAS Enterprise Miner or Weka, using the directed data mining techniques: Data Mining Course Work, DMU, UK appeared first on Students Assignment Help UK.